I was fortunate enough to attend this year’s Tesla AI Day. Tesla’s architecture has always been interesting to me because their hardware limitations drive advances in their software. Relative to other players in the industry:
- Low-spec sensors require ML- and data-first approaches, instead of adding more sensor hardware.
- Low-spec compute requires efficient model architectures. For example, preferring to share backbones among several tasks rather than adding more and larger task-specific models.
These are good directions that will help reduce the cost of machine learning and robotics, making them more relevant for everyday applications.

Elon Musk opens the presentation.
Below, I’ll discuss three topics that stood out to me:
- An LLM-inspired lane graph regression model
- Running the lane model efficiently on the Autopilot computer
- Increasing Dojo training tile utilization
Online lane graph predictions with a language model
Tesla described their approach for producing sparse lane graph predictions from a dense feature map produced by their 2D to 3D vision model. This is a key component in the autonomous vehicle software stack that enables the behavior system to reason about the possible actions of the vehicle and other agents.
We approached this problem like an image captioning task, where the input is a dense tensor, and the output text is predicted into a special language that we developed at Tesla for encoding lanes and their connectivities. In this language of lanes, the words and tokens are the lane positions in 3D space. The ordering of the tokens and predicted modifiers in the tokens encode the connective relationships between these lanes.
The architecture is inspired by transformer-based language models:
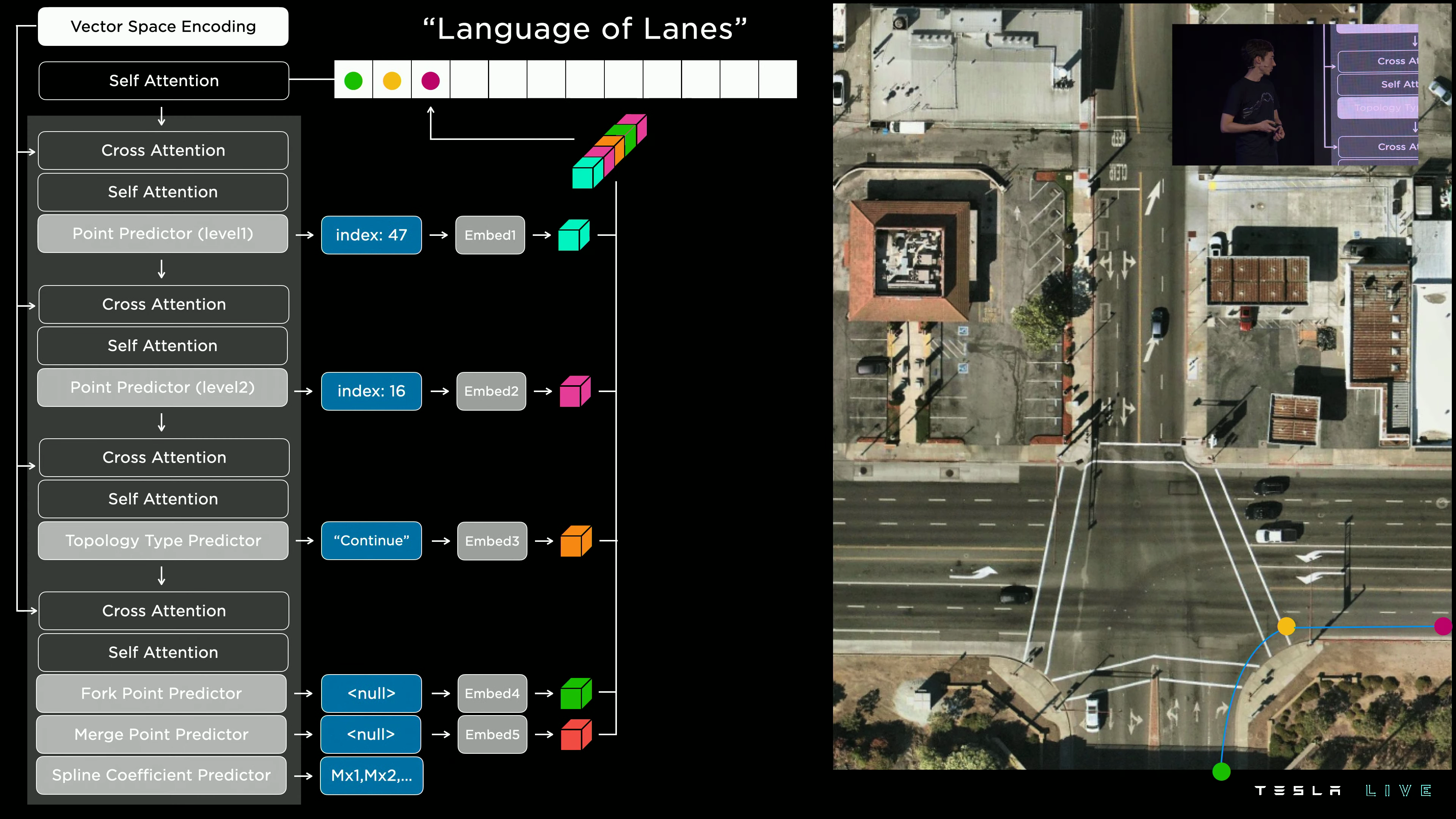
Tesla’s lane prediction model architecture.
Producing a lane graph from the model output sentence requires less postprocessing than parsing a segmentation mask or a heatmap. The DSL directly encodes the data structure needed by downstream consumers.
Recent advances in large language models and stable diffusion have produced impressive results approaching the quality and creativity of human-generated text and images. While they have clear applications in creative tools, they are limited by the need to have a human interpret the generated output.
I think the biggest impact of generative models will be in ingesting and producing structured data, such as Tesla’s lane graph DSL. This allows the learned component to be integrated into a larger software system. The models’ impact can grow with compute capacity rather than with the number of person-hours available to prepare inputs or view outputs.
Deploying the lane model: array indexing with dot products
Deploying the language model to the vehicle posed a challenge: Tesla’s neural network accelerator (“TRIP”) only supports multiply–accumulate operations.
When we built this hardware, we kept it simple and made sure it can do one thing ridiculously fast: dense dot products. But this architecture is autoregressive and iterative. […] The here challenge was: how can we do this sparse point prediction and sparse computation on a dense dot product engine?
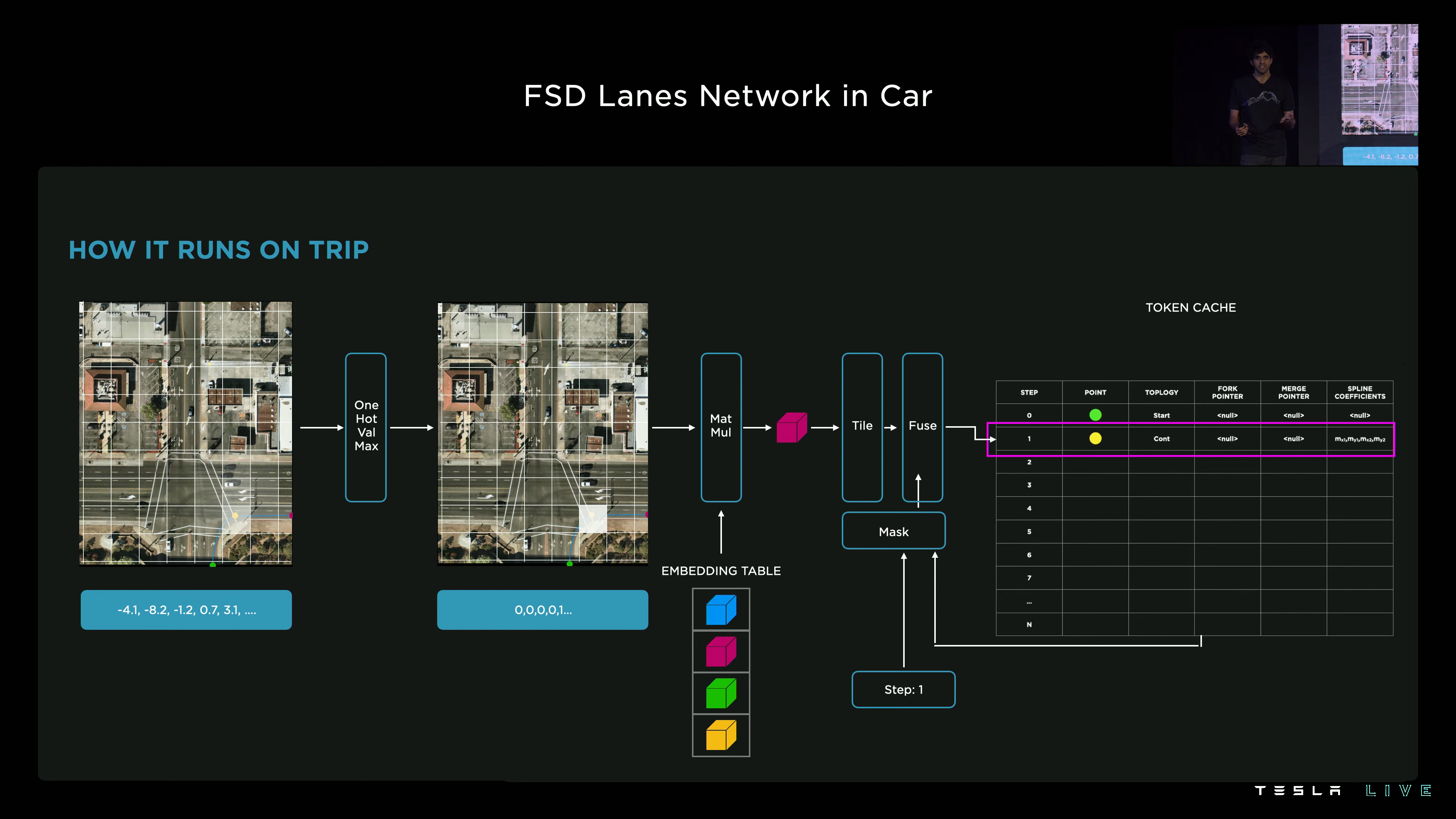
A matrix multiplication operation selects an entry from the embedding table.
They are rewriting indexing operations as a dot product with a one-hot vector. As an illustration, here’s how they might select the second item from a 1D lookup table with four entries:
\[\begin{bmatrix} 0 \\ 1 \\ 0 \\ 0 \\ \end{bmatrix}^\intercal \begin{bmatrix} X_0 \\ X_1 \\ X_2 \\ X_3 \\ \end{bmatrix}\]This feels like a workaround to get the model running on existing acclerator hardware developed with dense convolutions in mind. The current Autopilot computer, HW3, shipped in 2019. It was not clear that sparse operations would become so important to vision tasks. Unlike other companies, Tesla doesn’t operate its own fleet and unlike smartphone manufacturers, Tesla does not currently have the volume to spin new chips each year. They’ve made it work with the hardware they have.
The downside is that this implementation wastes FLOPs linearly with the number of entries in the lookup table. They definitely contain more than four items and the illustration suggests they might have two dimensions.
Transformers are becoming more prevalent in Tesla’s model architecture. It will be interesting to see whether future hardware runs these models more natively.
Dojo: Dealing with density
In last year’s presentation, Tesla introduced Dojo, the most unconventional system in Tesla’s tech stack.
- Its D1 accelerator chips contain a custom CPU with vector instructions, SRAM, and a chip-to-chip interconnect.
- The chips are arranged in a 2D grid and connected with their neighbors, forming a tile.
- Tiles are then packaged into a rack mount to connect to their neighbors.
- Several cabinets combine to form a cluster.
The overall strategy is to train arbitrarily large models by greatly increasing bandwidth and reducing latency between processors. This requires increasing density. All other design decisions are downstream of this strategy:
- Enclosure: 15 kW per tile, six tiles per tray. I don’t think any other accelerator comes close to this W/m³.
- Memory: SRAM instead of DRAM for storing weights and activations (nearly 700 MB per chip). On a more traditional computer architecture, this would be like storing a program’s working set in the CPU cache.
- Microarchitecture: The D1 accelerator chip doesn’t have much logic compared to other processors. They push the complexity to software. For example, Tesla performs static scheduling at compile time because the D1 CPU only supports in-order dispatch.
A blast from the past: VLIW
D1’s architecture reminds me of very long instruction word (VLIW) designs from the 1990s and early 2000s, such as Intel Itanium. Those processors failed in the market because instruction set compatibility dominated. When it came to improving performance, software developers would rather wait for next year’s microarchitecture than recompile their binaries for a new instruction set.
Deep learning workloads are different. Developers are highly motivated to increase performance. So far, they have been willing to adapt to architecture changes.
Feeding examples to the D1 accelerator
This year, Tesla provided additional details on how the training tiles are integrated into the rest of the datacenter.
There are several interface processors mounted below each tile. These standard x86 machines contain network interfaces and video decoding hardware to load training examples.

Interface processor details.
Tesla faced a problem when training a video model on Dojo. The utilization of the accelerator chips was only 4 percent.
With our dense ML compute, Dojo hosts effectively have 10x more ML compute than the GPU hosts. The data loaders running on this one host simply couldn’t keep up with all that ML hardware.
That’s right: the Dojo tiles achieved too much density relative to the x86 machines keeping them fed with training examples. The Dojo tiles spent most of their time waiting for data. For the system to run efficiently, the two machine types need to have a similar throughput.
They developed a custom DMA over Ethernet protocol that allows adding additional, external data loading hosts to communicate with the Dojo tiles. This improved utilization to an impressive 97 percent.
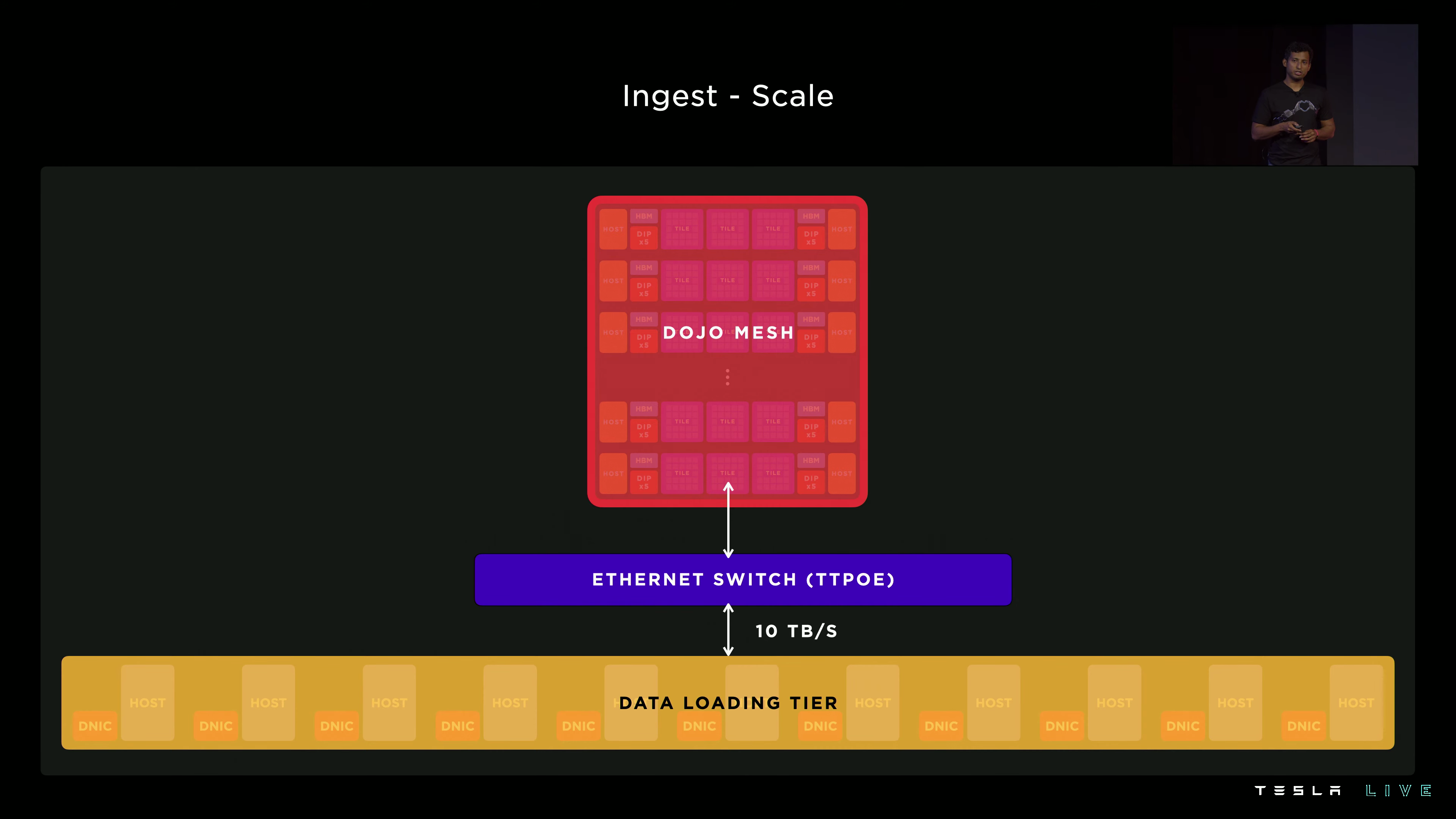
External data loading hosts connected over Ethernet. The diagram suggests the additional machines might be located in another rack.
However, the root cause of an unbalanced system remains unaddressed. While it is convenient to change the ratio between data loading machines and training accelerators by adding more machines to the network, I doubt this is the long-term architecture for Dojo. I would expect a future design to make the system more balanced.

The Cybertruck was the only show car we weren’t allowed to approach.