Tearing down the Rewind app
This ML-powered app records your entire screen, yet “doesn’t tax system resources.” How did they do it?
Rewind is a Mac app that records your computer’s screen and audio, allowing the user to scroll through a timeline of past screen recordings. Rewind also recognizes text, including text in videos and Zoom calls, allowing the user to perform full-text search on anything that has been displayed. Rewind is developed by the same team as Scribe.
Rewind also records Zoom meetings as a first-class feature. Whenever the user enters a meeting, Rewind asks to record and transcribe audio from all participants.
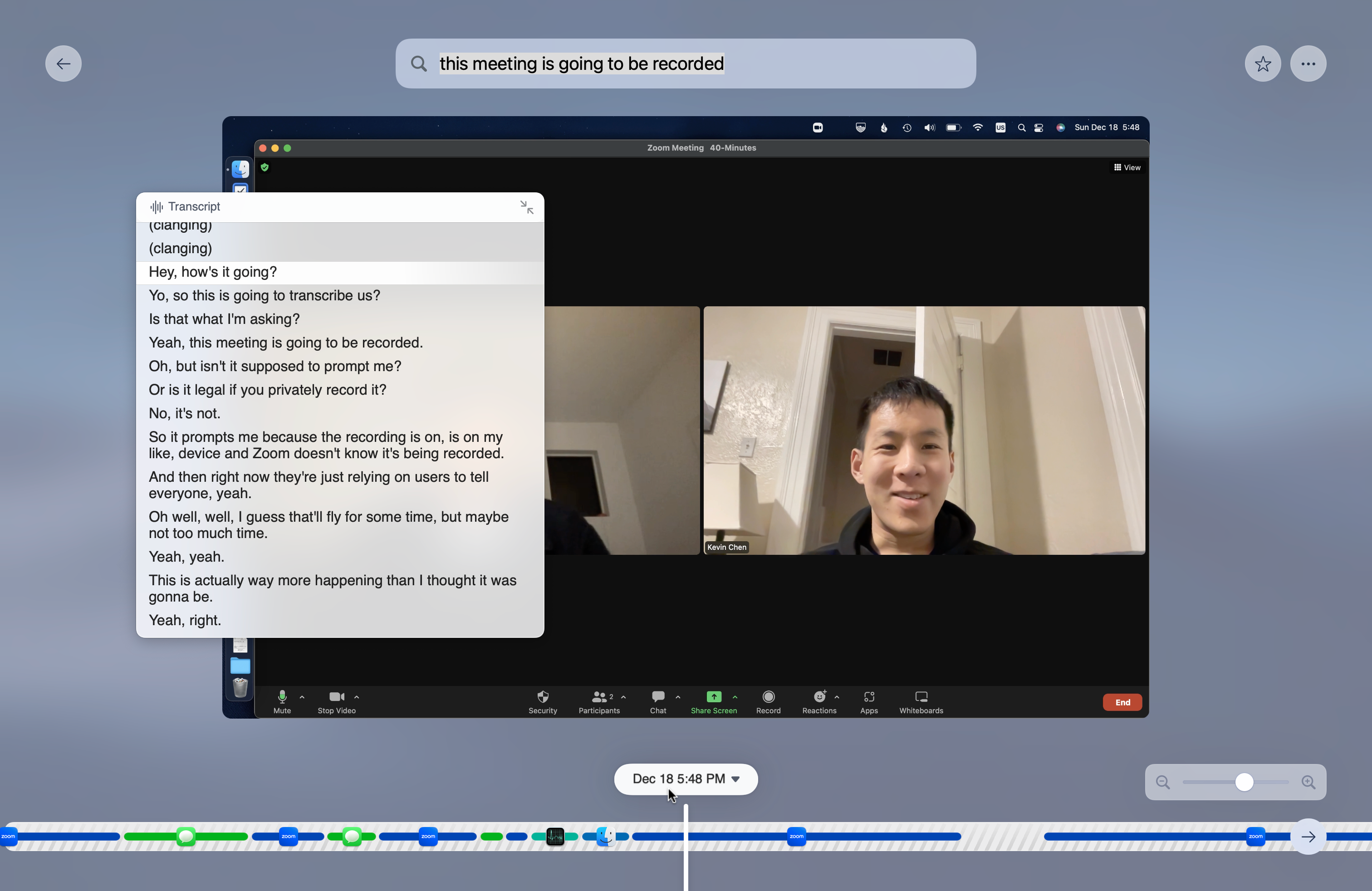
A Zoom call shown in the Rewind app’s history browser.
All indexing, including OCR and speech-to-text, happens locally. The developers claim that Rewind “doesn’t tax system resources, like CPU and memory, while recording” by taking advantage of accelerators built into the Apple M1 and M2. Given these claims, I was eager to sign up for the beta ($20/month, first month free) to find out how they pulled this off.
Contents
How it works: Overview
- Use accessibility APIs to identify the frontmost window.
- Store the timestamps to a SQLite database in the user’s Library folder.
- Take a screenshot of the screen that contains the frontmost window.
- If there are multiple screens, only the currently focused screen will be captured.
- Use ScreenCaptureKit to hide disallowed windows, including private browser windows and a user-defined exclusion list.
- OCR the screenshot on-device using Apple’s Vision framework, the same pipeline that powers Live Text.
- Store the inference results to a SQLite database.
- Compress the screenshot sequence to an H.264 video with FFmpeg.
- Store videos in the user’s Library folder.
Additionally, if the user joins a Zoom call and enables transcription through Rewind:
- Transcribe the audio on-device using the OpenAI Whisper model.
- Store the transcripts and speaker information in a SQLite database.
In the following sections, I’ll provide details on how I came to these conclusions.
Analyzing the Rewind app
Application Bundle
After installation, I poked through the Rewind.app bundle.
Executables:
Rewind: the Cocoa applicationRewind Helper: a non-UI binary
Other notable files include:
Resources/ggml-base.en.bin: The model weights for the OpenAI Whisper transcription model in the whisper.cpp, likely for Zoom call transcription. The SHA-1 taken on my local machine (137c40403d78fd54d454da0f9bd998f78703390c) matches the file from the weights repo.Resources/favicons: A directory of 912 favicons for popular websites, stored as PNG images. Examples includeamazon_com.png,dropbox_com.png,youtu_be.png, etc. These are used in the timeline view when the frontmost app is a web browser, instead of showing the browser’s app icon.Frameworks/Sparkle.framework: Despite installing through a.pkg, Rewind uses Sparkle for updates.
Frameworks
After loading into a disassembler, the Rewind binary contains references to:
- whisper.cpp
- VisionKit
- ImageAnalyzer — API for running Live Text inference and accessing results
- ImageAnalyzerOverlayView — displays Live Text results and allows the user to copy text
- Sentry — telemetry
The Rewind Helper contains a statically linked FFmpeg.
Permissions
Upon launch, Rewind requests permissions to:
- record the screen
- record the microphone
- control other applications (accessibility).
Recording the microphone is optional if the user doesn’t want to transcribe Zoom meeting audio.
Excluded Applications & Private Browsing
Rewind allows the user to exclude apps from its recording. By default, Rewind also excludes private windows from several popular browsers.
In this example, I’ve opened three windows (listed from back to front):
- TextEdit
- Safari (regular)
- Safari (Private Browsing)
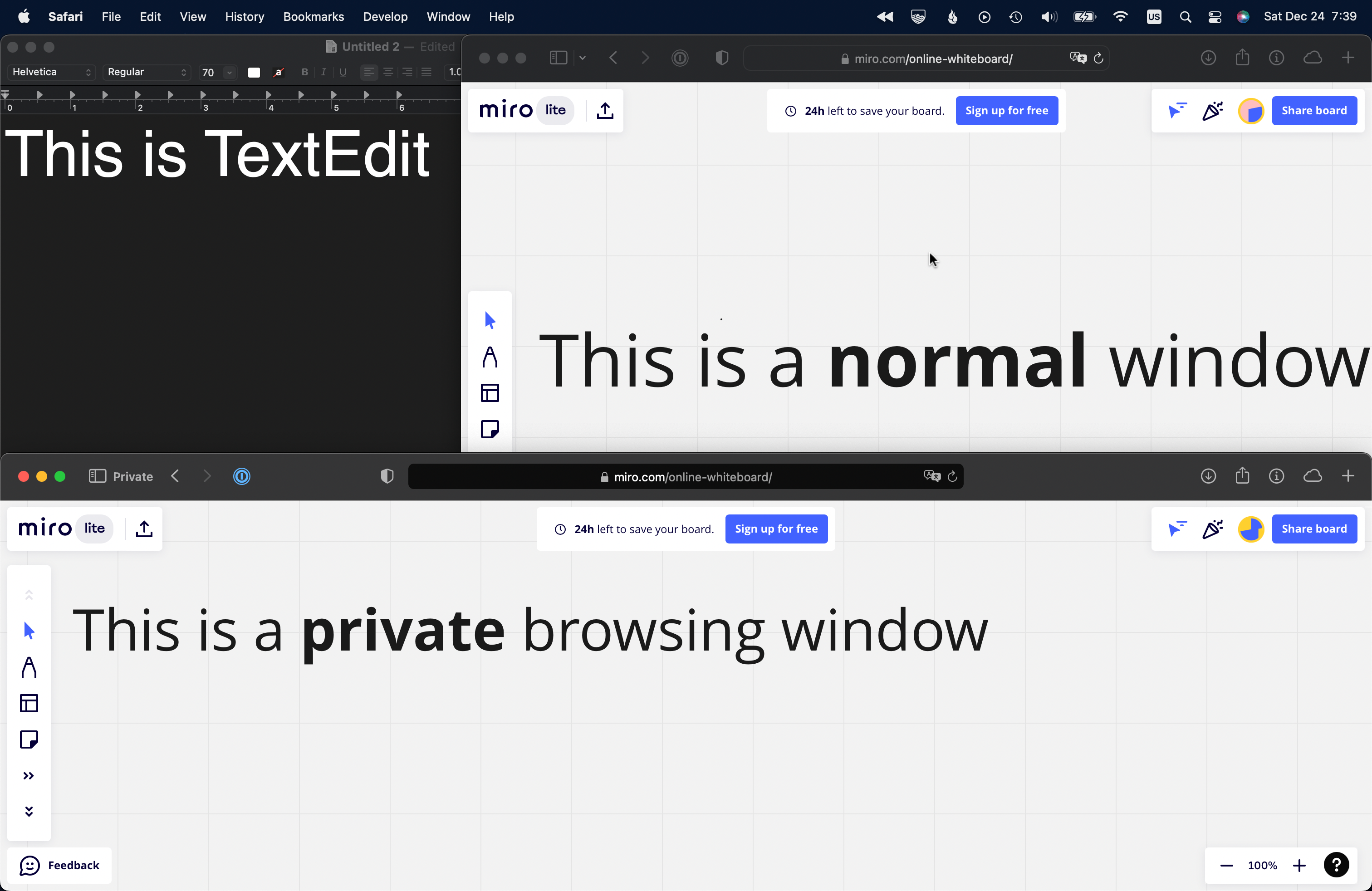
Top: My actual desktop. Bottom: What Rewind sees.
Rewind’s screenshot excludes the private browsing window and the menu bar — and reveals additional content previously occluded by the private window.
This suggests that Rewind uses Apple’s ScreenCaptureKit, which allows filtering by window and can recomposite the desktop based on the input parameters. (The legacy CGDisplayCapture API can only capture the entire screen or individual windows. The app developer would have to perform their own compositing.)
Storage Format
Rewind stores all screen recordings and transcripts to:
~/Library/Application Support/com.memoryvault.MemoryVault
There are three items in this directory:
(1) chunks: H.264 videos
A directory of timestamped movie files. Surprisingly, the date format contains colons.
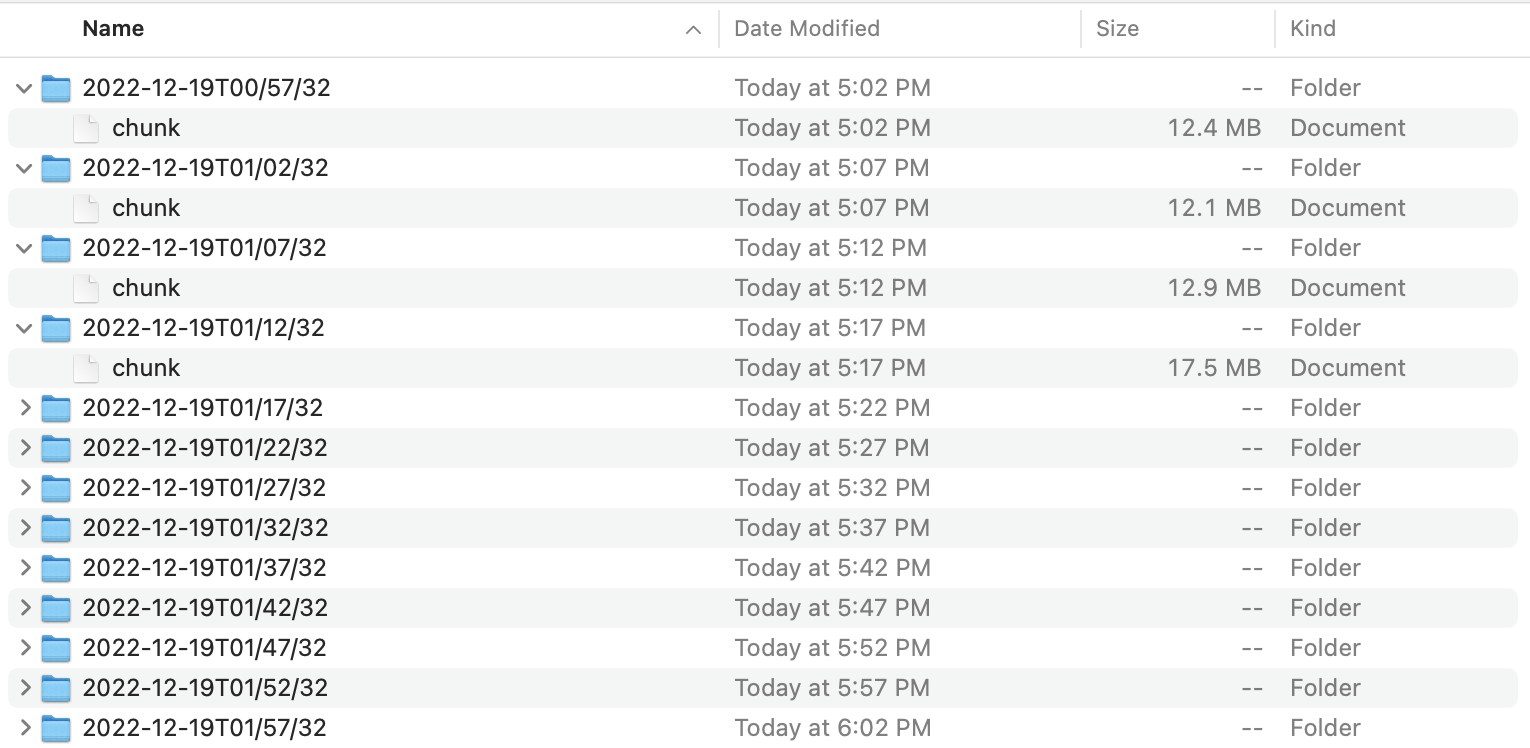
The chunks directory.
Each chunk file is an MP4 container:
$ cd ~/Library/Application\ Support/com.memoryvault.MemoryVault/chunks/2022-12-19T00:57:32
$ file chunk
chunk: ISO Media, MP4 Base Media v1 [ISO 14496-12:2003]
Inspecting the file with VLC, we find that it contains a single H.264 stream, about 5 minutes long at 0.5 fps.
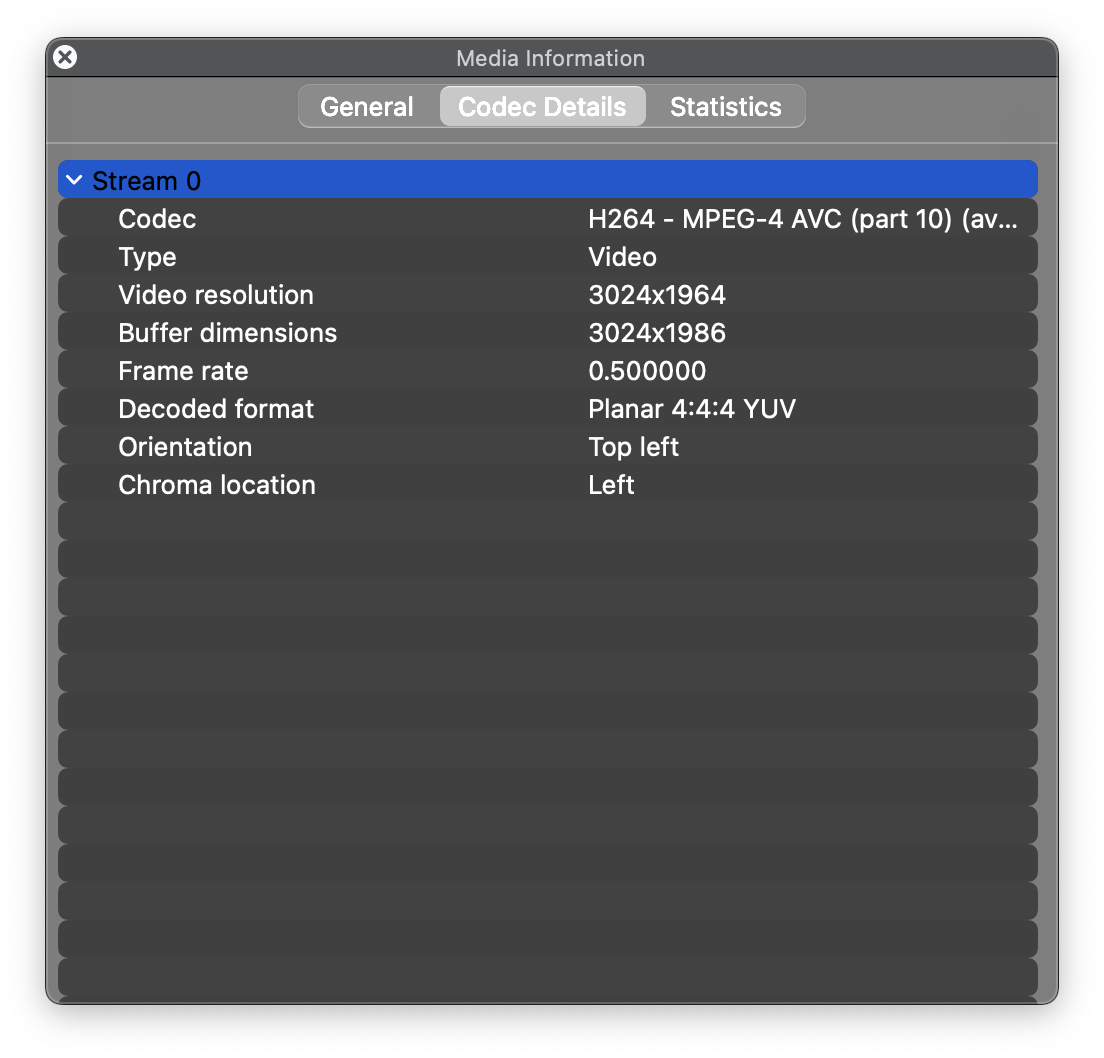
VLC inspector on a chunk file.
(2) temp: PNG screenshots
This directory contains a series of screenshots. A new screenshot is created every two seconds.
With a screen resolution of 3024 × 1964 (14-inch MacBook Pro), the app writes about 1–2 MB/s of PNGs when displaying text. The exact throughput depends on the total screen size and content being shown. In the worst case, such as when playing back a full-screen movie, each screenshot might exceed 10 MB.
A PNG file gets created every two seconds.
(3) db.sqlite3: Metadata
Rewind uses this SQLite database to store video file metadata, focused app metadata, OCR results, and call transcripts. Here are the key tables:
frame contains a row for each video frame.
SELECT * FROM frame LIMIT 10
Query Results
| id | createdAt | imageFileName | segmentId | videoId | videoFrameIndex | isStarred | encodingStatus |
|---|---|---|---|---|---|---|---|
| 1 | 2022-12-19T00:57:32.890 | 2022-12-19T00:57:32.788 | 1 | 1 | 0 | 0 | success |
| 2 | 2022-12-19T00:57:36.845 | 2022-12-19T00:57:36.742 | 1 | 1 | 1 | 0 | success |
| 3 | 2022-12-19T00:57:38.827 | 2022-12-19T00:57:38.738 | 2 | 1 | 2 | 0 | success |
| 4 | 2022-12-19T00:57:40.833 | 2022-12-19T00:57:40.741 | 2 | 1 | 3 | 0 | success |
| 5 | 2022-12-19T00:57:43.573 | 2022-12-19T00:57:43.494 | 3 | 1 | 4 | 0 | success |
| 6 | 2022-12-19T00:57:44.807 | 2022-12-19T00:57:44.723 | 4 | 1 | 5 | 0 | success |
| 7 | 2022-12-19T00:57:46.794 | 2022-12-19T00:57:46.722 | 4 | 1 | 6 | 0 | success |
| 8 | 2022-12-19T00:57:48.854 | 2022-12-19T00:57:48.763 | 4 | 1 | 7 | 0 | success |
| 9 | 2022-12-19T00:57:50.848 | 2022-12-19T00:57:50.759 | 4 | 1 | 8 | 0 | success |
| 10 | 2022-12-19T00:57:52.836 | 2022-12-19T00:57:52.744 | 4 | 1 | 9 | 0 | success |
search_content contains raw OCR results, and node maps them to positions on frame. There can be multiple node per frame.
SELECT * FROM search_content LIMIT 1
Query Results
| docid | c0text | c1otherText |
|---|---|---|
| 1 | ? Advanced… 000 ###: Security & Privacy Q Search Click the lock to make changes… | 4:54 PM 4:54 PM y Access! Q ock Auctions 12/15/22 )23 12/15/22 Date Received out… |
SELECT * FROM node LIMIT 10
Query Results
| id | frameId | nodeOrder | textOffset | textLength | leftX | topY | width | height | windowIndex |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 1 | 0.467398302591349 | 0.597970651366107 | 0.00672236248460967 | 0.013157853170445 | 0 |
| 2 | 1 | 1 | 2 | 9 | 0.399312973022461 | 0.59765262753272 | 0.0522676955821902 | 0.0116193030208916 | 0 |
| 3 | 1 | 2 | 12 | 3 | 0.0610130221344704 | 0.0570757653384834 | 0.0364272095436274 | 0.0161139305601729 | 0 |
| 4 | 1 | 3 | 16 | 23 | 0.163880813953488 | 0.0565509518477043 | 0.113372092912819 | 0.0179171332422108 | 0 |
| 5 | 1 | 4 | 40 | 8 | 0.381177325581395 | 0.0565509518477043 | 0.0414244182655039 | 0.0156774914800299 | 0 |
| 6 | 1 | 5 | 49 | 31 | 0.0875726744186047 | 0.598544232922732 | 0.127906976671512 | 0.0145576707649976 | 0 |
| 7 | 1 | 6 | 81 | 13 | 0.107422983923624 | 0.499536426710789 | 0.0514842521312625 | 0.014643243018617 | 0 |
| 8 | 1 | 7 | 95 | 18 | 0.10719476744186 | 0.458566629339306 | 0.0821220929505814 | 0.0145576707606783 | 0 |
| 9 | 1 | 8 | 114 | 10 | 0.106081352677456 | 0.417901666006876 | 0.0499914524167083 | 0.0125384870061416 | 0 |
| 10 | 1 | 9 | 125 | 7 | 0.287038004675577 | 0.376678364274216 | 0.0357664684916651 | 0.0107925261255073 | 0 |
search is a virtual table constructed from search_content using the SQLite FTS (full-text search) extension.
sqlite> .schema search
CREATE VIRTUAL TABLE "search" USING fts4("text", "otherText", tokenize=porter)
/* search(text,otherText) */;
segment contains a row for each instance of the focused application changing. This data appears to be gathered from the accessibility API, because the timestamps and window titles are exact. Additionally, there’s an optional column for the browser URL when the focused application is Safari, Chrome, or Arc. I’m not sure how this information is captured.
SELECT * FROM segment WHERE id > 85 LIMIT 10
Query Results
| id | appId | startTime | endTime | windowName | browserUrl | browserProfile | type |
|---|---|---|---|---|---|---|---|
| 86 | com.apple.Safari | 2022-12-19T01:07:16.816 | 2022-12-19T01:07:18.815 | Storage | Rewind Help Center | https://help.rewind.ai/en/collections/3698681-storage | screenshot | |
| 87 | com.apple.Safari | 2022-12-19T01:07:18.815 | 2022-12-19T01:07:42.808 | How does Rewind compression work? | Rewind Help Center | https://help.rewind.ai/en/articles/6706118-how-does-rewind-compression-work | screenshot | |
| 88 | com.apple.finder | 2022-12-19T01:07:42.808 | 2022-12-19T01:07:44.793 | Desktop — Local | screenshot | ||
| 89 | com.apple.ActivityMonitor | 2022-12-19T01:07:44.793 | 2022-12-19T01:08:06.847 | Activity Monitor | screenshot | ||
| 90 | com.facebook.archon | 2022-12-19T01:08:06.847 | 2022-12-19T01:08:32.845 | Messenger | screenshot | ||
| 91 | com.apple.ActivityMonitor | 2022-12-19T01:08:32.845 | 2022-12-19T01:08:36.840 | Activity Monitor | screenshot | ||
| 92 | com.apple.finder | 2022-12-19T01:08:36.840 | 2022-12-19T01:08:40.844 | Desktop — Local | screenshot | ||
| 93 | com.apple.finder | 2022-12-19T01:08:40.844 | 2022-12-19T01:08:44.844 | Library | screenshot | ||
| 94 | com.apple.finder | 2022-12-19T01:08:44.844 | 2022-12-19T01:08:50.839 | Application Support | screenshot | ||
| 95 | com.apple.finder | 2022-12-19T01:08:50.839 | 2022-12-19T01:08:54.833 | screenshot |
SELECT * FROM segment WHERE type != "screenshot"
Query Results
| id | appId | startTime | endTime | windowName | browserUrl | browserProfile | type |
|---|---|---|---|---|---|---|---|
| 349 | ai.rewind.audiorecorder | 2022-12-19T01:47:37.511 | 2022-12-19T02:03:54.695 | audio |
transcript_word contains a row for each word of Zoom call transcripts. This storage is rather inefficient given the app’s current functionality, but appears to be setting up for a future UI that can match the transcript to the call audio.
SELECT * FROM transcript_word LIMIT 20 OFFSET 24
Query Results
| id | segmentId | speechSource | word | timeOffset | fullTextOffset | duration |
|---|---|---|---|---|---|---|
| 25 | 349 | me | how’s | 51000 | 93 | 1000 |
| 26 | 349 | me | it | 52000 | 99 | 1000 |
| 27 | 349 | me | going? | 53000 | 102 | 1000 |
| 28 | 349 | me | Yo, | 54000 | 109 | 250 |
| 29 | 349 | me | so | 54250 | 113 | 250 |
| 30 | 349 | me | this | 54500 | 116 | 250 |
| 31 | 349 | me | is | 54750 | 121 | 250 |
| 32 | 349 | me | going | 55000 | 124 | 250 |
| 33 | 349 | me | to | 55250 | 130 | 250 |
| 34 | 349 | me | transcribe | 55500 | 133 | 250 |
| 35 | 349 | me | us? | 55750 | 144 | 250 |
| 36 | 349 | me | Is | 56000 | 148 | 400 |
| 37 | 349 | me | that | 56400 | 151 | 400 |
| 38 | 349 | me | what | 56800 | 156 | 400 |
| 39 | 349 | me | I’m | 57200 | 161 | 400 |
| 40 | 349 | me | asking? | 57600 | 165 | 400 |
| 41 | 349 | me | Yeah, | 58000 | 173 | 249 |
| 42 | 349 | me | this | 58249 | 179 | 249 |
| 43 | 349 | me | meeting | 58499 | 184 | 249 |
| 44 | 349 | me | is | 58749 | 192 | 249 |
Finally, clip deletion is temporarly enqueued in the purge table. It appears to contain a row per deleted frame or chunk. The referenced rows in frame, rows in video, and the chunk files get deleted soon after user request. But the purge table only gets cleared the next time the app starts up.
If the user deletes all clips contained in a chunk file, the chunk file is also deleted. In other cases, the app implements soft-deletion by removing the SQLite metadata only.
SELECT * FROM purge
WHERE path >= '2022-12-25T00:19:26'
ORDER BY path
LIMIT 5
Query Results
| path | fileType |
|---|---|
| 2022-12-25T00:19:26.962 | image |
| 2022-12-25T00:19:26/chunk | video |
| 2022-12-25T00:19:28.943 | image |
| 2022-12-25T00:19:30.951 | image |
| 2022-12-25T00:19:32.931 | image |
Resource Usage & Battery Life
CPU usage while recording on my 14-inch MacBook Pro with M1 Pro:
Rewinduses about 20% CPU continuouslyRewind Helperspikes over 200% CPU every time the temporary PNG images are compressed to a H.264 video
I suspect that Rewind also indirectly consumes resources through WindowServer because Rewind requests filtered windows. This may require WindowServer to perform additional compositing just for Rewind. However, I haven’t been able to measure this conclusively.
Storage usage:
- Screen recordings (
chunks): 180 MB / hour - Metadata, OCR results, and call transcripts (
db.sqlite3): 26 MB / hour - Console logs: 4 MB / hour
These numbers were calculated after the first 11 hours of using Rewind. My workload is a mix of text-heavy (reading, writing) and image-heavy (video editing) tasks. The storage used will vary depending on workload: for example, a text- and Zoom-heavy workload will generate a larger SQLite database.
Overall, running Rewind reduces my battery life by about 20–40 percent.
Ideas for Improvement
Below are some areas the Rewind app’s architecture could be improved. It’s understandable that the developers prioritized shipping an MVP over polishing these details. However, if the pricing remains $20 per month, users will expect a lot of polish in the released app.
Battery Life
Reduced battery life is my primary pain point when using Rewind.
PNG encoding. Rewind could encode the screenshots directly to H.264, instead of temporarily writing PNG images. This would eliminate throwaway work to encode and decode PNGs.
It would also eliminate 0.6–3.0 GB / hour of writes, or 4–19 TB / year assuming continuous operation. From a NAND wear perspective, this is unlikely to be a problem: modern SSDs can handle well over 500 TB written per TB of capacity. However, generating a large amount of I/O remains a battery life issue.
Video encoding. Rewind encodes with FFmpeg. I wasn’t able to determine whether FFmpeg was using the M1’s Media Engine (video encode/decode accelerator). Update (February 2, 2023): Rewind appears to encode video on the CPU (libx264 via FFmpeg). Matteo Contrini and Andy Xu pointed out that it’s possible to read encoder settings from an ffmpeg-encoded movie. Matteo writes:
Regarding the ffmpeg part, if they’re not overriding metadata you can find which encoder was used with ffmpeg itself, or ffprobe.
For example, if you ffprobe a video file encoded by VideoToolbox (hw encoding) you would find
h264_videotoolboxin theencoderfield of the metadata. If it’s x264, you’d findlibx264.
Rewind appears to use software encoding — see libx264 below. This appears consistently on files generated by Rewind version 0.6309 (the version originally tested) through 0.7312 (the current version as of February 2, 2023).
$ ffprobe ~/Library/Application\ Support/com.memoryvault.MemoryVault/chunks/2023-01-31T22\:33\:11/chunk
ffprobe version 5.1.2 Copyright (c) 2007-2022 the FFmpeg developers
[...]
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from '/Users/Kevin/Library/Application Support/com.memoryvault.MemoryVault/chunks/2023-01-31T22:33:11/chunk':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
encoder : Lavf59.30.100
Duration: 00:05:00.00, start: 0.000000, bitrate: 497 kb/s
Stream #0:0[0x1](und): Video: h264 (High) (avc1 / 0x31637661), yuv420p(progressive), 3024x1964, 496 kb/s, 0.50 fps, 0.50 tbr, 16384 tbn (default)
Metadata:
handler_name : VideoHandler
vendor_id : [0][0][0][0]
encoder : Lavc59.42.103 libx264
As of Rewind 0.7168 (released on January 27, 2023), the app now defers H.264 encoding when the user’s device is running on battery power. This resolves the battery impact of video encoding.
However, this approach still strikes me as wasteful. Rewind might compete with the user for CPU time in some cases, and at a minimum, it heats up the user’s machine unnecessarily.
Rewind already requires Apple Silicon. This allows them to assume that hardware-accelerated encoding is always available. Perhaps they have other reasons not to use it, such as needing to support a wider range of encoder settings.
On-device inference frequency. OCR currently runs on every image (0.5 Hz). It’s possible that OCR can be subsampled or deferred entirely when running on battery without compromising the search experience. Any deferred images could be scanned the next time the user plugs in their computer or opens the Rewind UI.
Storage Format
The current directory structure and schemas are performant enough for a user base that only has a few months of recordings at most. Although Rewind can set a retention period, the default setting retains recordings forever, and it’s clear from the marketing materials that indefinite retention is the intended use case. The storage formats could be changed slightly to account for an ever-growing archive:
Database. SQLite is quite performant; however, the text search table also grows quickly (26 MB / hour on my machine). Putting all text into a single table may cause problems in the future. For example, backup software may have trouble with a large and constantly changing file, especially Time Machine on HFS+ and others that don’t support block-level deduplication. For users with retention enabled, performing a SQLite VACUUM after deleting a large number of records may take a long time and require lots of scratch space.
Directory structure. Currently, each video clip receives its own subdirectory in the chunks directory. Filesystems become less performant when listing and traversing directories as the number of children grows, even modern filesystems that use hash tables. A common solution is to create multiple levels of subdirectories using the prefix of the desired directory name. For Rewind’s timestamp directories (such as 2022-12-19T00:57:32), the prefixes could be some concatenation of the year, month, and day.
Security
Rewind currently doesn’t encrypt data at rest. Any app with full disk access and any attacker who encounters an unlocked computer has the ability to read recordings from all time, including soft-deleted clips.
Rewind could encrypt files on disk using a shared secret stored in the macOS Keychain. Access to Keychain secrets can be configured on a per-app, per-secret basis.
For increased security, Rewind could implement public-key cryptography, where the public key is used to append recordings and the private key is required to search them. Users would need to authenticate to unlock the search UI.
Privacy
Rewind currently allows users to exclude apps from recording and to delete specific past recordings. It would be great to combine these features by offering bulk deletion by app, time range, URL, etc.
Ideally, deletions would always remove the underlying imagery, even if it requires an expensive re-encode of the chunk files to support partial deletion.
Conclusion
The Rewind app is a clever and helpful user interface built on top of components such as Apple’s VisionKit and OpenAI’s Whisper. Imagery is compressed with H.264 and text search uses SQLite FTS.
As a developer, it’s cool to see that such advanced features can be built without training any ML models. The ever-growing collection of powerful, pretrained models continues to lower the barrier to entry for building ML-powered apps. On the other hand, I would also feel concerned that “fast follower” type competitors can easily clone apps like Rewind.
As a user, I’m excited to be served by increasingly intelligent software that, in addition to competing on the quality of machine learning, must also compete on user experience.
Appendix
Rewind App
Version: 0.6309
Bundle ID: com.memoryvault.MemoryVault
Database Schema
Table names:
- doc_segment
- frame
- node
- purge
- search
- search_content
- search_docsize
- search_segdir
- search_segments
- search_stat
- segment
- segment_video
- tokenizer
- transcript_word
- video
Full schema:
CREATE TABLE IF NOT EXISTS "frame" ("id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "createdAt" TEXT NOT NULL, "imageFileName" TEXT NOT NULL, "segmentId" INTEGER REFERENCES "segment" ("id"), "videoId" INTEGER REFERENCES "video" ("id"), "videoFrameIndex" INTEGER, "isStarred" INTEGER NOT NULL DEFAULT (0), "encodingStatus" TEXT);
CREATE TABLE sqlite_sequence(name,seq);
CREATE TABLE IF NOT EXISTS "node" ("id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "frameId" INTEGER NOT NULL REFERENCES "frame" ("id"), "nodeOrder" INTEGER NOT NULL, "textOffset" INTEGER NOT NULL, "textLength" INTEGER NOT NULL, "leftX" REAL NOT NULL, "topY" REAL NOT NULL, "width" REAL NOT NULL, "height" REAL NOT NULL, "windowIndex" INTEGER);
CREATE TABLE IF NOT EXISTS "segment" ("id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "appId" TEXT, "startTime" TEXT NOT NULL, "endTime" TEXT NOT NULL, "windowName" TEXT, "browserUrl" TEXT, "browserProfile" TEXT, "type" TEXT NOT NULL DEFAULT ('screenshot'));
CREATE TABLE IF NOT EXISTS "video" ("id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "frameDuration" REAL NOT NULL, "height" INTEGER NOT NULL, "width" INTEGER NOT NULL, "path" TEXT NOT NULL DEFAULT (''), "captureType" TEXT, "fileSize" INTEGER);
CREATE INDEX "index_frame_on_segmentid_createdat" ON "frame" ("segmentId", "createdAt");
CREATE INDEX "index_node_on_frameid" ON "node" ("frameId");
CREATE INDEX "index_frame_on_createdat" ON "frame" ("createdAt");
CREATE VIRTUAL TABLE "search" USING fts4("text", "otherText", tokenize=porter)
/* search(text,otherText) */;
CREATE TABLE IF NOT EXISTS 'search_content'(docid INTEGER PRIMARY KEY, 'c0text', 'c1otherText');
CREATE TABLE IF NOT EXISTS 'search_segments'(blockid INTEGER PRIMARY KEY, block BLOB);
CREATE TABLE IF NOT EXISTS 'search_segdir'(level INTEGER,idx INTEGER,start_block INTEGER,leaves_end_block INTEGER,end_block INTEGER,root BLOB,PRIMARY KEY(level, idx));
CREATE TABLE IF NOT EXISTS 'search_docsize'(docid INTEGER PRIMARY KEY, size BLOB);
CREATE TABLE IF NOT EXISTS 'search_stat'(id INTEGER PRIMARY KEY, value BLOB);
CREATE VIRTUAL TABLE tokenizer USING fts3tokenize(porter)
/* tokenizer(input,token,start,"end",position) */;
CREATE INDEX "index_frame_on_isstarred_createdat" ON "frame" ("isStarred", "createdAt");
CREATE INDEX "index_frame_on_videoid" ON "frame" ("videoId");
CREATE INDEX "index_segment_on_starttime" ON "segment" ("startTime");
CREATE TABLE IF NOT EXISTS "doc_segment" ("docid" INTEGER NOT NULL UNIQUE REFERENCES "search" ("docid"), "segmentId" INTEGER NOT NULL REFERENCES "segment" ("id"), "frameId" INTEGER REFERENCES "frame" ("id"));
CREATE INDEX "index_doc_segment_on_segmentid_docid" ON "doc_segment" ("segmentId", "docid");
CREATE INDEX "index_doc_segment_on_frameid_docid" ON "doc_segment" ("frameId", "docid");
CREATE TABLE IF NOT EXISTS "segment_video" ("segmentId" INTEGER NOT NULL REFERENCES "segment" ("id"), "videoId" INTEGER NOT NULL REFERENCES "video" ("id"), "startTime" TEXT NOT NULL, "endTime" TEXT NOT NULL);
CREATE INDEX "index_segment_video_on_segmentid_starttime_endtime" ON "segment_video" ("segmentId", "startTime", "endTime");
CREATE TABLE IF NOT EXISTS "transcript_word" ("id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "segmentId" INTEGER NOT NULL REFERENCES "segment" ("id"), "speechSource" TEXT NOT NULL, "word" TEXT NOT NULL, "timeOffset" INTEGER NOT NULL, "fullTextOffset" INTEGER, "duration" INTEGER NOT NULL);
CREATE INDEX "index_transcript_word_on_segmentid_fulltextoffset" ON "transcript_word" ("segmentId", "fullTextOffset");
CREATE INDEX "index_segment_on_appid" ON "segment" ("appId");
CREATE TABLE IF NOT EXISTS "purge" ("path" TEXT NOT NULL, "fileType" TEXT NOT NULL, UNIQUE ("path", "fileType"));